Copy, Slice and Merge
It is a common vice to leave a lot of data in a table or dataframe, because the skills are missing to park them somewhere else and to only get them back when needed.
Rename vs. Shallow Copy vs. Deep Copy
Sometimes, you need to rename a dataframe and sometimes you need to make a real copy. Problems can emerge when you intend to do the one, but technically you do the other.
Example: You slice a dataframe and rename that particular fraction, instead of copying it. Then, you also change the original dataframe, which might lead to wrong results later that are difficult to find.
In Julia, there is quite some implicit logic in this distinction.
You only rename a dataframe when you equal it to a new name, e.g.
df2 = df
A so-called “shallow copy” of the dataframe is made with the standard copy command.
dfCopy = copy(df)
A shallow copy copies some but not all of the dataframe.
In order to make a real, independent copy of your dataframe, you need to use deepcopy
dfDeepCopy = deepcopy(df)
Changes to dfDeepCopy do not affect df.
Slice
Let use again the dataframe holding the cars data.
filename = "cars.csv" path = "./ZZ_Data/" relname = path * filename df = CSV.read(relname, DataFrame)
Differences to Python include:
- You need always to specify both rows and columns
- You need to specify the first and last element, if you do not select all.
- The last element is specified using end
Columns
Get selected column numbers
colNumbers = [1, 2, 3, 5, 8] df2 = df[:, colNumbers]
Mind that you need to specify the rows with the colon (:) sign, i.e. here you select all rows.
Get selected column names
keepCols = [:Name, :Cylinders, :Horsepower, :Origin] df2 = df[:, keepCols]
Instead of slicing, the select command can be used as well
keepCols = [:Name, :Cylinders, :Horsepower, :Origin] dfS = select(df, keepCols)
Rows
Get selected row numbers
Create a dataframe, d2, that contains rows 3, 4, 5, 6 and 7.
df2 = df[3:7, :]
Create a dataframe, 2, that contains every 100th row.
df2 = df[1:100:end, :]
Rectangular
A rectangular selection from with the original dataframe
df3 = df[4:8, 5:7]
Merge
Concatenation
In some cases, a concatenation is sufficient.
In Julia, there is
- horizontal concatenation hcat
- vertical concatenation vcat
Let’s work with an example that is not too trivial. Three accounts with data for January and February.
df1Jan = DataFrame(Accounts = ["Account_1", "Account_2", "Account_3"], Jan = [1111, 2211, 3311]) df1Feb = DataFrame(Accounts = ["Account_1", "Account_2", "Account_3"], Feb = [1122, 2222, 3322])
Horizontal Concatenation
As both dataframes contain the same column name, which is not allowed in the resulting dataframe, Julia must be enabled to make the columns unique.
dfHJanFeb = hcat(df1Jan, df1Feb, makeunique=true)
Vertical Concatenation
For vertical concatenation, you need the same column names. Hence, another dataframe is required.
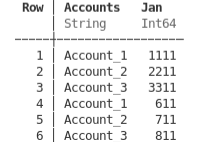
df2Jan = DataFrame(Accounts = ["Account_1", "Account_2", "Account_3"], Jan = [611, 711, 811])
Vertical concatenation simply appends the second dataframe underneath the first one.
df12Jan = vcat(df1Jan, df2Jan)
Join
When you want to merge dataframes on a specific column, then a join can be used to bring them together.
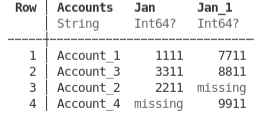
Let’s make up an additional dataframe with slightly different accounts for January.
df3Jan = DataFrame(Accounts = ["Account_1", "Account_3", "Account_4"], Jan = [7711, 8811, 9911])
An outerjoin keep all values from both dataframes for the specified column.
df13Jan = outerjoin(df1Jan, df3Jan, on=:Accounts, makeunique=true)
Depending on your use case choose from: innerjoin, leftjoin, rightjoin, outerjoin, semijoin, antijoin, or crossjoin.