K-Means
K-Means is intuitive, powerful and easy to implement, see References.
The focus here is to use KMeans with dataframes as much as possible.
Solution
The algorithm ‘K_Means’ is here applied to the iris data set.
‘K_Means’ can be applied to learn more about an unknown data structure. For testing this assumption, ‘K-Means’ is here applied to a well-known underlying data structure to find out, if this data structure can be retrieved from the data.
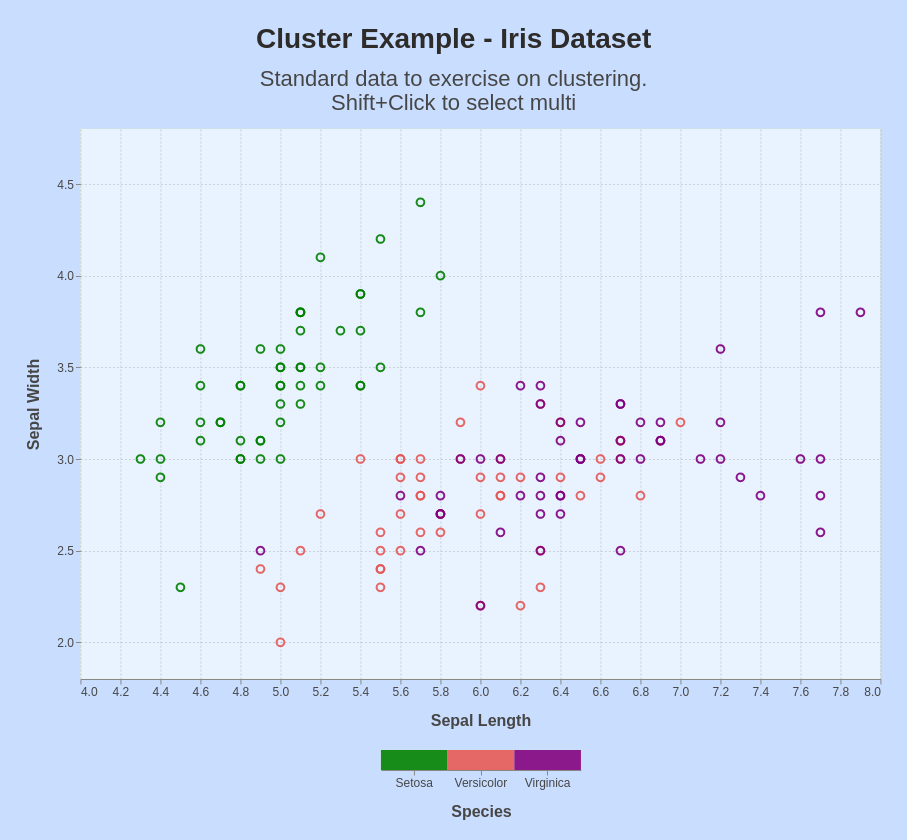
A standard example for classification.
Solution idea and some details
The library ‘cluster’ by sklearn is used here.
Columns of the dataframe can be directly forwarded to the K-Means API. The type of the columns must be numeric. However, it is not necessary to convert them to numpy arrays.
For the famous Iris example, it is well-known that the number of cluster must be 3, because 3 types of flowers are used to get the data. In real scenarios, this number is typically unknown and must be determined differently, e.g. using the ‘elbow-method’.
from sklearn.cluster import KMeans featureCols = ["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"] myModel = KMeans(n_clusters=3, random_state=17) myModel.fit(df[featureCols])
The K-Means algorithm does not need the target (or labels). There are no “y-values’.
Results
As a result, you get the computed center of clusters. You can assign the result directly to a dataframe.
dfCenters = pd.DataFrame(data=myModel.cluster_centers_)
Each row in the dataframe was assigned by the algorithm to a cluster. For 3 clusters, each row got one of the values 0, 1 or 2. You can directly add a column with these model labels.
df["Prediction_LE"] = myModel.labels_
Label Encoder
When you know the true cluster and this cluster has a name of type string, then you might want to have the predicted value to be the respective string. For the Iris example, you know that the first row is a flower called “Virginica”. Then, the predicted value, if correct, should be “Virginica” as well. You can achieve this mapping using the label encoder available in the preprocessing of sklearn. First you need to tell this label encoder (le) the relation between the clusters numbers and the true names.
from sklearn import preprocessing le = preprocessing.LabelEncoder() df["LE"] = le.fit_transform(df.Label)
At the end, you can use the ‘trained’ label encoder to inverse this relaltionship and get the string values back from the cluster numbers.
df["Prediction_Label"] = le.inverse_transform(df.Prediction_LE)